
ENTRY_AGENTI 2026-02-13VIEWS: -- STATUS: DECRYPTED
Agentic RAG
AI RAG Tech
End_of_Header_Data
Protocol_Feedback
Community Thoughts.
0Nodes
Initialize_Message...
Ready to Send
No active signals detected.
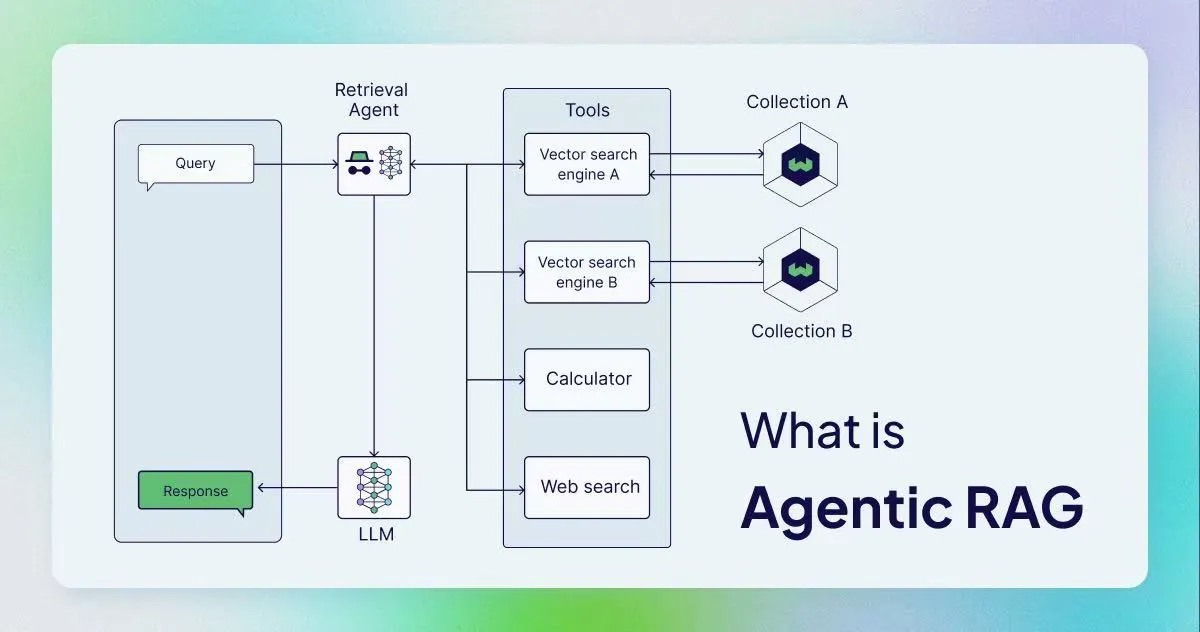
Agentic RAG 是利用人工智能代理来辅助**检索增强生成(RAG)**的过程,Agentic RAG系统就是在RAG流程中加入Agent来提高适应性和准确性。 相比于传统的RAG,Agentic RAG允许LLM从多个来源进行信息检索,并处理更复杂的工作流程。
检索增强生成(Retrieval-Augmented Generation, RAG)最本质的价值,是把 LLM 的“参数化记忆”(模型训练学到的知识)与“非参数化记忆”(外部知识库、网页、数据库)组合起来,让模型在回答时能引用外部证据,提升知识密集型任务的准确性与可更新性。RAG 的经典论文将其作为一种“检索器 + 生成器”的组合式框架,并在开放域问答等任务中验证了这类方法的有效性。
但工程上你会很快发现:RAG 的天花板往往不在“会不会检索”,而在“检索之后怎么用、用得对不对、检索错了怎么办”。传统 RAG 常见痛点包括:
Agentic RAG 可以用一句话概括:
在 RAG 流程中加入“智能体(Agent)作为控制层”,让系统能自主决定:要不要检索、去哪检索、检索不到怎么办、检索到了是否可信、要不要再检索一次,并通过工具调用与多步规划把复杂问题拆开解决。
你可以把它理解为:
在 LangGraph 的官方教程里,“检索代理(retrieval agent)”的定位就非常典型:让 LLM 自己决定是否需要从向量库检索上下文,或直接回答。这类“可选择检索”的设计是 Agentic RAG 最常见的入门形态。
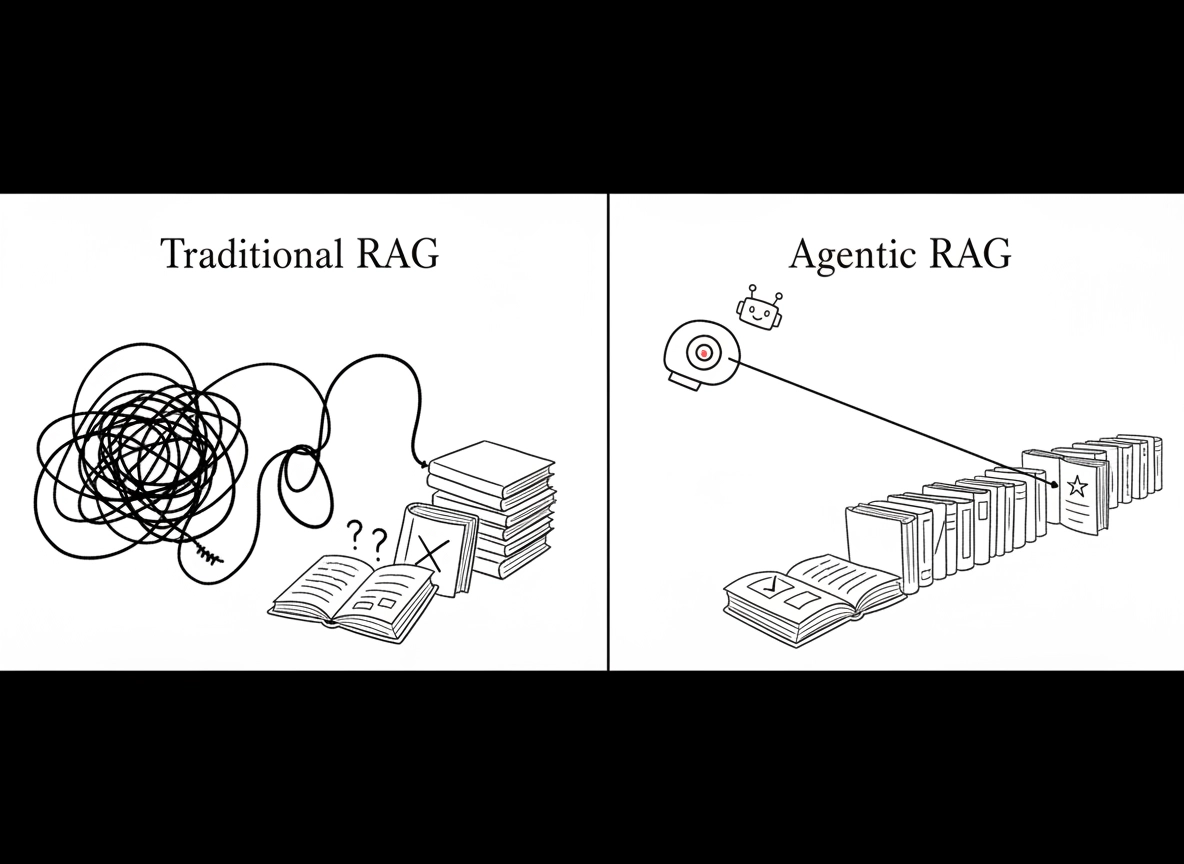
传统 RAG 系统就像一名严格按手册办事的图书管理员。如果你向他索要一份特定文件,他会找到它并为你朗读相关部分。然而,如果文件中存在错别字或指向了一个缺失的文件,他会直接停止工作并上报错误。他不会去核实这些信息对于你的目标而言是否“准确”或“有用”,他只是在执行既定的检索程序。
与传统 RAG 相比,智能体 RAG (Agentic RAG) 带来了以下几个显著的提升:
灵活性 (Flexibility):智能体 RAG 应用能够从多个外部知识库中提取数据,并支持使用外部工具。而标准 RAG 流程通常仅将大模型与单一外部数据集连接。例如,许多企业级 RAG 系统只是将聊天机器人与包含公司私有数据的知识库进行配对。
适应性 (Adaptability):传统 RAG 系统属于反应式的数据检索工具,仅针对特定查询查找相关信息。此类系统无法适应不断变化的上下文,也无法访问其他数据。为了获得理想结果,通常需要进行大量的提示词工程 (Prompt Engineering)。与此同时,智能体 RAG 实现了从“基于规则的静态查询”向“自适应智能问题解决”的转型。多智能体系统通过协作和相互校验,进一步提升了处理能力。
准确性 (Accuracy):传统 RAG 系统不会对自身结果进行验证或优化,其表现是否达标仍需人工辨别。系统本身无法判断所找数据是否正确,也无法确认是否成功将其整合以实现上下文感知的生成。然而,AI 智能体可以对之前的流程进行迭代,从而随着时间的推移不断优化结果。
可扩展性 (Scalability):得益于智能体网络之间的协同工作、多外部数据源的接入,以及工具调用和规划能力,智能体 RAG 具有更强的可扩展性。开发者可以构建灵活且易于扩展的系统,以处理更广泛的用户查询。
多模态 (Multimodality):智能体 RAG 系统受益于多模态大模型的最新进展,能够处理更丰富的数据类型,如图像和音频文件。多模态模型可以处理结构化、半结构化和非结构化数据。例如,近期发布的几款 GPT 模型除了标准文本生成外,已经能够生成视觉和音频内容。
相比之下,智能体 RAG 系统 (Agentic RAG) 更像是一个咨询顾问团队。如果他们在数据中发现了矛盾,他们会停下来,交叉引用其他来源,并对差异进行“推理”。他们会调用各种工具——如计算器、网页搜索或专业数据库——来填补信息空白。他们不仅会向你交付搜寻到的结果,还会提供一套经过验证的、多步骤的解决方案,并在过程中不断自我审视,以确保最终产出真正解决了你的问题。
虽然智能体 RAG 通过函数调用、多步推理和多智能体系统优化了输出结果,但它并不总是最佳选择。更多的智能体意味着更高的成本,因为系统通常需要消耗更多的 Token。虽然智能体 RAG 在解决问题的能力上有所提升,但大模型也会引入延迟,因为模型生成多步输出需要更长的时间。
最后,智能体并非始终可靠。取决于任务的复杂程度和所使用的智能体类型,它们可能会在执行中遇到困难甚至失败。智能体之间的协作并不总是顺畅,甚至可能出现资源竞争。系统中的智能体越多,协作就越复杂,出现问题的概率也随之增加。此外,即使是设计最严密的 RAG 系统,也无法完全消除幻觉 (Hallucinations) 的风险。
智能体 RAG 的核心在于将一种或多种 AI 智能体 (AI Agents) 整合进 RAG 系统中。例如,一个系统可能包含多个专门从事信息检索的智能体:一个负责查询外部数据库,另一个则负责梳理电子邮件和网页搜索结果。
开发者可以利用 GitHub 上的 LangChain、LlamaIndex 以及编排框架 LangGraph 以极低的成本实验这些架构。若结合 IBM Granite™ 或 Meta Llama-3 等开源模型,设计者在享受更高可观测性的同时,还能降低支付给 OpenAI 等供应商的费用。
智能体 RAG 系统通常包含以下几类 AI 智能体:
Semantic Search(语义搜索)
把“查询”和“文档/段落”都编码成向量,用相似度检索返回最相关的内容;通常输出是排序后的结果列表/片段,并不天然保证“回答已完成”。OpenSearch、Elastic 等文档把它描述为基于向量嵌入与向量检索的语义检索流程。
One-shot Agentic Search(单次智能体搜索)
LLM 先做一次“规划/拆解/改写/选库/选策略”,然后把检索执行(可能包含多子查询、并行检索、混合检索)一次性跑完,最后合成结果;但它通常不会进入“检索不足→反思→再检索”的闭环。你可以把它理解为“计划一次,然后一口气执行”。在一些 agent 实现里,这种范式被明确描述为“先把行动计划好,再一次性执行”。
Agentic Search(智能体搜索/全流程智能体搜索)
LLM 像研究员一样做一个闭环:规划→检索→评估→发现缺口→调整策略→再检索→综合,直到满足停止条件。Chroma 的文档把它概括为计划、执行、评估、迭代与综合的流程。
Query
└─> Embedding
└─> Vector DB / kNN
└─>Top-k Results (chunks/docs)
└─> (可选)Rerank /Filter
└─> Return results / feedto RAG
Query
└─> LLM Planner(一次)
├─ 生成子查询/改写query
├─ 选择检索类型(keyword/vector/hybrid)
└─ 选择数据源(一个或多个)
└─> Execute Retrievals(并行/串行,但通常不再反思迭代)
└─> Synthesize(合成答案/摘要 + 引用)
对应到 OpenSearch 的概念上,更偏向“flow agents(只做查询规划、低延迟、低成本)”。
对应到 Azure AI Search,则是“规划产生子查询 → 子查询并行执行 → 合成与引用”。
Query
└─> PLAN(拆解/设预算/设停止条件)
└─> SEARCH(检索/读网页/查库/调用工具)
└─> EVAL(证据是否充分?是否冲突?缺口在哪里?)
├─ insufficient-> REFINE(改写/换源/更细子问题)-> 回到 SEARCH
└─ sufficient-> SYNTHESIZE(带引用的最终回答)
这就是 Chroma 文档里强调的“plan→execute→evaluate→iterate→synthesize”。
虽然智能体 RAG 适用于任何传统 RAG 的应用场景,但由于其对算力需求更高,它更适合需要跨多个数据源进行查询的情况。智能体 RAG 的典型应用包括: