读者定位:熟悉 React,但希望把 RSC(React Server Components,React 服务端组件)理解到“能设计系统”的深度。本文面向工程实践,不会回避细节。
下面的内容分三层:
为什么要有 RSC (设计哲学)它到底如何运行 (概念与机制)在工程中如何做对 (实践与边界)
文中嵌入了 RSC Explorer 的示例,你可以直接在结构树上观察 Server/Client 边界。
1. 设计哲学:把 UI 视为“可计算的树”
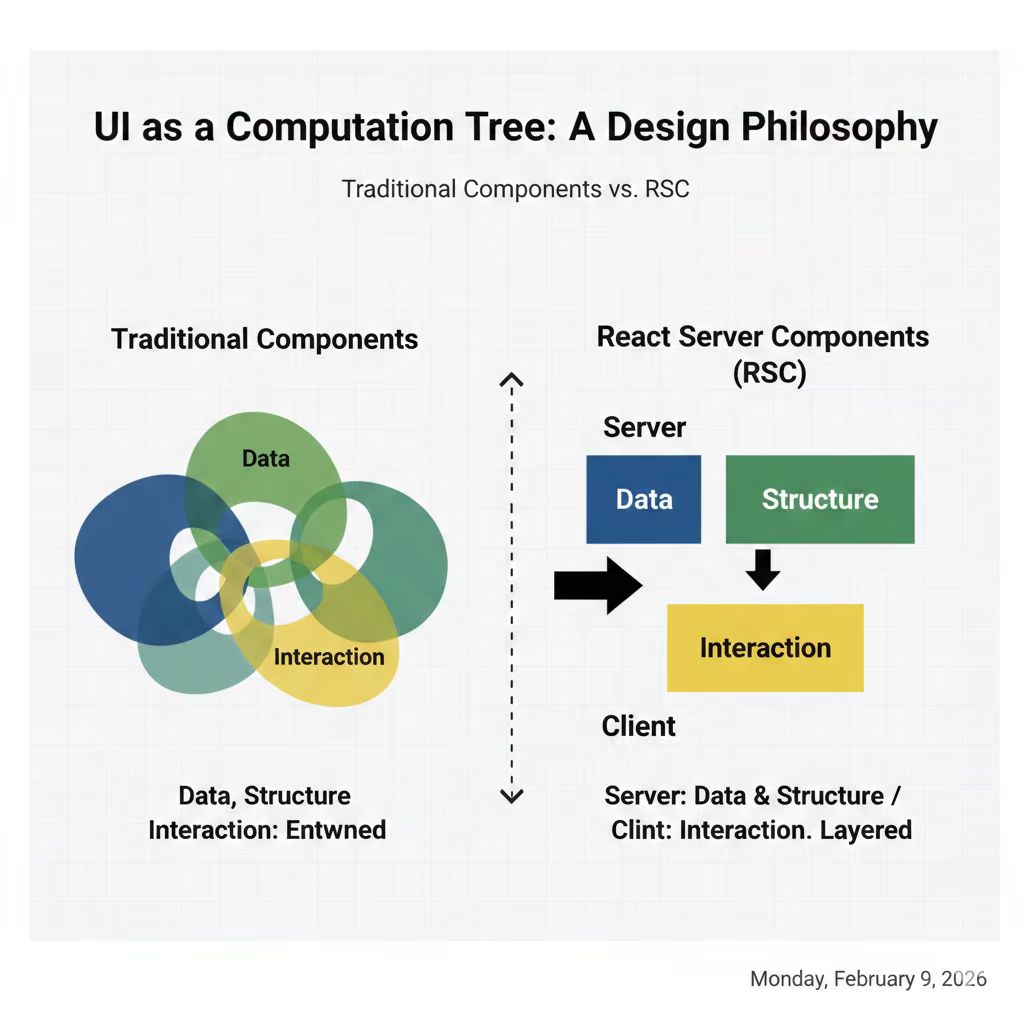
RSC 的核心不是“更快”,而是让 UI 的结构更接近数据与计算的真实形态 。在传统 CSR/SSR 中,工程实践常把数据获取、权限判断、视图拼装和交互逻辑混在一起,结果是组件树“长得像页面”,但并不“像计算”。RSC 反过来要求你从计算与依赖关系出发构建 UI:组件树首先是计算图,然后才是视觉结构 。当你把它当成计算图,你就必须回答一个问题:这段 UI 的数据在哪边?计算在哪边?交互在哪边?
从这个问题出发,RSC 形成了三条“硬哲学”。第一,就近计算(Compute near data) 。所有不依赖浏览器能力的计算尽量在服务端完成,因为数据就在这里,权限与安全边界也在这里。第二,交互留给浏览器(Interaction on client) 。交互意味着事件、动画、即时状态,它们天然属于浏览器,只应该承载交互而不是数据计算。第三,组件树反映数据依赖(Tree follows data dependencies) 。组件的拆分不是“前后端分工”,而是“数据从哪来、何时可得”。这条哲学决定了你如何组织组件树:从数据域拆分,而不是从技术域拆分。
这些哲学并不是抽象口号,它们直接改变你对 UI 的组织方式。RSC 把“结构”与“交互”分离,把“数据计算”从“视觉声明”里抽出来,让 UI 变成一棵可推理的树。Server Components 是数据驱动的结构,Client Components 是交互驱动的容器 ,这不是分工建议,而是架构约束。
图1:设计哲学对比——传统组件混合数据/结构/交互,RSC 分层为 Server 结构与 Client 交互。
2. 概念与原理:RSC 是“拆树 + 序列化”
2.1 树如何拆
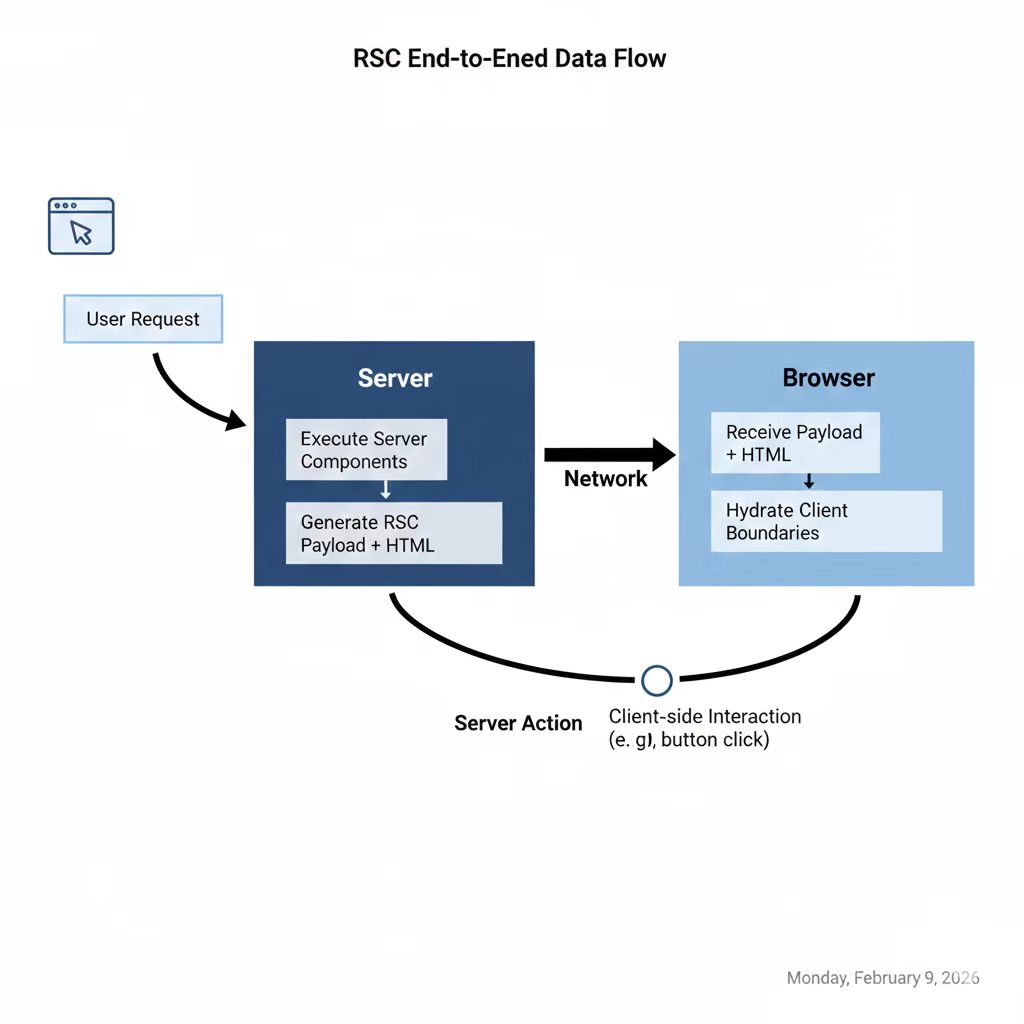
RSC 的核心动作不是“渲染”,而是把组件树拆成两块并形成稳定的边界 。具体来说,React 在构建树时会识别 use client 边界,把它视为“客户端岛屿”。边界外的所有节点在服务端执行并得到结果,边界内的节点被标记为“客户端可执行模块引用”,它们不会在服务端运行,只会携带必要的 props 穿过边界。于是,树被拆成“可计算的服务端部分”与“需要激活的客户端部分” 。
这里的关键不在“把代码拆成两份”,而在“把树拆成两段”。你写的组件依旧是一个整体,但在运行时,这棵树被切成了两层:服务端负责生成结构与数据,客户端只激活交互边界 。这个切分是可组合的:你可以在任何子树上声明 client 边界,而不是被迫在页面层级整体切分。
服务端执行 Server Components 后,会生成一份可被客户端消费的 RSC payload 。客户端接收这份 payload,只对 use client 边界内部进行 hydration。换句话说,客户端并不“重建整棵树”,而是“补全边界内的交互”。
图2:RSC 端到端数据流——请求、服务端执行、payload/HTML、客户端 hydration 与 action 回写。
下面是最小示例(纯 Server Component):
2.2 async 组件与流式渲染
RSC 的天然形态是 async 组件,因为服务端执行意味着你可以直接 await 数据。这里的变化不是“语法更舒服”,而是渲染模型发生了变化 :组件不再是“同步地返回 JSX”,而是“异步地返回结构”。这使得 React 可以在服务端对树进行 分段计算与流式输出 ,而不是等待整棵树完成之后再返回一个整体。
Suspense 在这里扮演的角色是“渲染切分器”。你可以把慢数据的子树包在 Suspense 中,让服务端先输出可用的部分,再随着数据完成逐段补全。这和传统 SSR 不同:SSR 是“拼完整 HTML 再输出”,而 RSC 是“拼出树的前半部分就输出,并继续流式补齐”。流式输出不是锦上添花,它直接决定了你如何组织组件与数据获取逻辑。
下面示例展示了 async Server Component 与 Suspense 的协作:
这一点直接影响工程结构:服务端是“组装与并发”,客户端是“交互与增量” 。工程上更重要的是:你会自然倾向于把数据读取上移到服务端组件,把交互留在少量边界内,而不是把整个页面都变成 client。结果是更低的 hydration 成本、更清晰的依赖关系、以及可预测的渲染路径。
2.3 核心实现:RSC payload 到底是什么
RSC 的关键不是把 JSX 直接变成 HTML,而是把 “组件树的结果”序列化为一种可传输的结构 。你可以把它理解成:React 在服务端执行组件函数,把结果编码成一份“可重放的树描述”,浏览器用它重建 Server Component 的结果,并把 Client Component 的边界替换成可交互的节点。 这意味着 RSC 的“输出”不是单一的 HTML,而是一个包含结构、数据与引用的复合产物,它允许 React 在浏览器侧精确地“复用已算好的树”,而不是重新执行同一段逻辑。
这里可以把 RSC payload 想成一种专门为 React 组件树设计的中间表示。它记录了“这棵树长什么样”“哪些节点是纯文本/元素”“哪些节点必须在客户端激活”。这份 payload 本质上是 React 能理解的树语义,而不是浏览器能直接渲染的 DOM 语义。于是它更接近“组件语言”,而不是“页面语言”。用更工程化的语言:RSC payload = “结构 + 数据 + client 引用”。 HTML 只是其中一层表现,真正驱动 UI 的是 payload 本身。
在实现上,payload 还要解决“跨边界数据如何带过去”的问题。Server Component 可以传递给 Client Component 的数据必须是可序列化的结构,这背后是一个强约束:你不能把函数、类实例、不可序列化对象直接跨边界传递。 这个约束迫使我们把交互与数据拆开,从而让组件树更清晰、更可维护。
图3:RSC payload 结构——树节点、文本节点、client 引用与 props 序列化。
2.4 服务端序列化是如何工作的
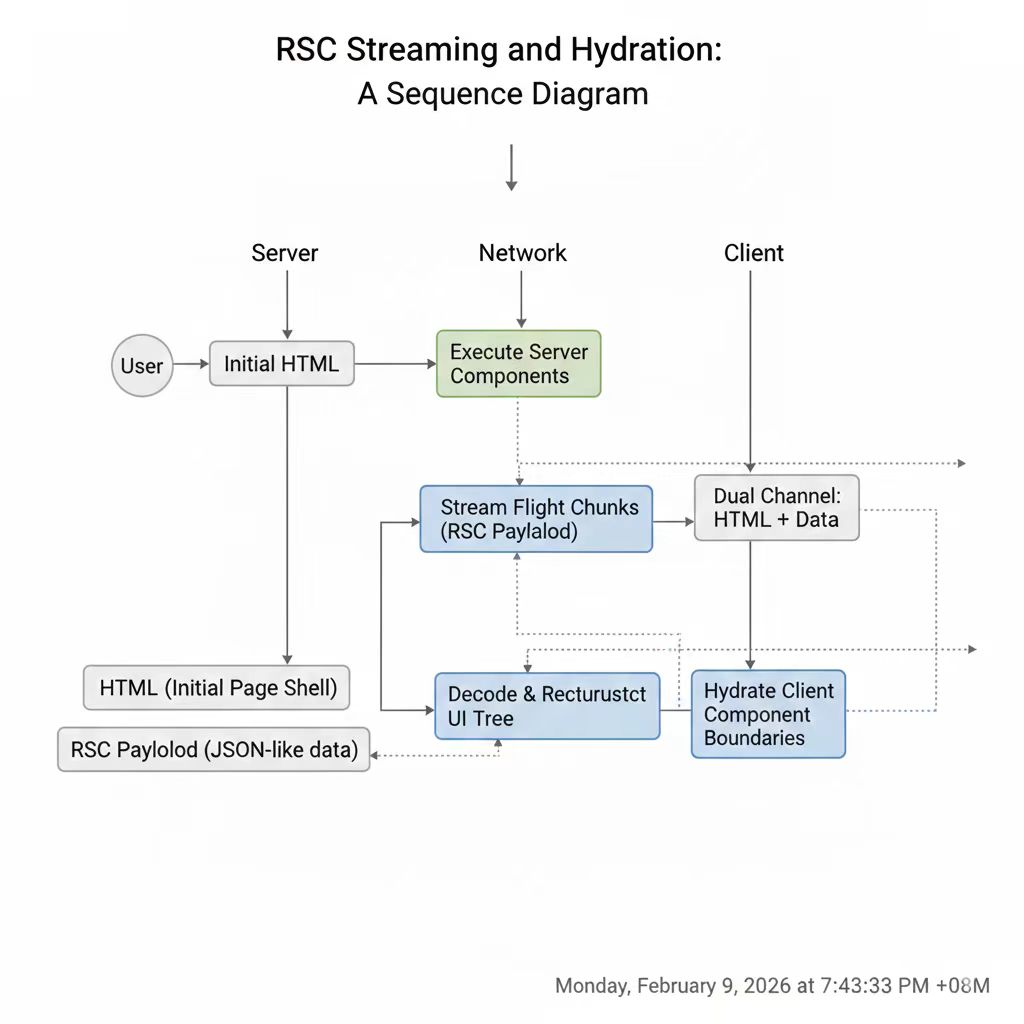
服务端执行 RSC 时,首先会真正运行 Server Components,这一步得到的是一棵包含元素、文本和 client 引用的树。接下来 React 把这棵树编码成 Flight 数据流:这不是一次性输出,而是可以按需切片的流式结构,允许服务器在数据尚未完全可用时先输出可用的部分。最后服务端会同时发送 HTML 和 payload,HTML 保障首屏可见性,payload 负责补全结构和边界。
浏览器侧的职责更明确:它先反序列化 payload,把 Server Component 的结果复用回来,然后只对 use client 边界内部做 hydration。换句话说,客户端不是“重新执行整棵树”,而是只激活必要的交互节点 。这就是为什么 RSC 能显著降低 hydration 成本:它不是“少渲染”,而是“少激活”,并且激活发生在结构已经确定的前提下。
图4:序列化与反序列化时序——Flight 分片流式传输与客户端 hydration。
2.5 RSC 的约束与设计权衡
RSC 的序列化机制天然带来约束,而这些约束恰恰构成了工程上的“护栏”。Server 只能输出可序列化结果,Client 只能接收结构化数据,这意味着交互逻辑不能偷偷跨边界传播;你必须明确划分职责。与此同时,边界越小,客户端负担越轻,但边界太碎又可能增加组件复杂度,因此需要在“清晰度”与“可维护性”之间取得平衡。
这些约束不是坏事。它们迫使我们把“交互逻辑”与“数据组装”分开,把“可计算的 UI”与“可交互的 UI”拆成两层。这正是 RSC 的价值所在:通过序列化约束,强制你写出结构正确的树。
3. use client:边界声明,不是性能开关
use client 的作用不是“让它更快”,而是声明:这块树由客户端负责 。这条语义非常硬,意味着边界内部无法访问服务端能力,边界之外也无法依赖浏览器状态。换句话说,use client 是“语义边界”,而不是“优化开关”。它决定了这棵树的哪些部分会进入客户端 bundle,并在浏览器中执行。
工程上更重要的是:use client 会改变数据与计算的路径。边界越大,你越容易把数据拉到客户端再处理,结果是 bundle 变重、hydration 增加、状态变复杂。边界越小,你越倾向于在服务端完成计算,把交互限制在局部。因此真正的优化不是“少写 use client”,而是“把它放在正确的地方”。
下面这个示例展示了典型的边界切分方式:服务端负责结构与数据,客户端只包裹交互局部。
经验法则: 只把真正需要交互的“按钮、输入、动画、事件层”放在 client,其余都留在 server。
4. use server:跨边界的动作协议
use server 是一种调用协议 :浏览器发起动作,服务器执行并返回结果。它不是组件,而是“可被客户端触发的服务端函数”。
例子:
// app/(admin)/posts/actions.ts
"use server";
export async function savePost(formData: FormData) {
const title = String(formData.get("title") ?? "");
const body = String(formData.get("body") ?? "");
// 写入数据库或文件系统
}
客户端调用方式示例:
"use client";
export function PostEditor({ onSave }: { onSave: (fd: FormData) => Promise<void> }) {
return (
<form action={onSave}>
<input name="title" placeholder="Post title…" />
<textarea name="body" placeholder="Write something…" />
<button type="submit">Save</button>
</form>
);
}
对应的绑定示例:
要点:
use server 是显式边界 ,不是“普通函数”。它天然形成应用层 API:输入定义清晰,便于校验、日志、审计和缓存。
5. use cache:让服务端计算变得可复用
在 RSC 里,缓存不是“优化细节”,而是决定结构正确性 的工具。use cache 的作用是将某段 server 计算显式地定义为可缓存 。
一个直观的示意:
export async function getPostList() {
"use cache";
// 查询数据库 / 读取文件
return await fetchPosts();
}
实践建议:
以函数边界缓存 :比在组件里散落缓存更可维护。并行化获取(Promise.all) :避免数据瀑布(waterfall)。最小化序列化 :不要把大对象丢进 client props。
在 Next.js 里,缓存控制还能通过 cacheTag / cacheLife 一类 API 做细粒度失效策略。实践上,“写操作”必须显式触发失效,否则缓存会让 UI 表现“看起来没更新”。
6. 结构文档:一棵合理的 RSC 树
一个健康的 RSC 结构通常是:上层都是 Server,局部边界用 Client 隔开交互 。
Page (Server)
├─ Shell (Server)
│ ├─ Sidebar (Server)
│ ├─ Content (Server)
│ │ ├─ Article (Server)
│ │ └─ Comments (Client)
│ └─ Footer (Server)
└─ Toasts (Client)
RSC Explorer 的结构示例:
7. 工程化最佳实践(结合 React/Next.js 性能模式)
这一节把 RSC 的“理念”落到具体工程约束上,很多来自真实 Next.js 性能实践:
消除数据瀑布(waterfall) :并行启动独立请求,晚一点再 await,让 Suspense 做流式拆分。服务端缓存去重 :用 React 的缓存能力做请求去重,避免同一渲染阶段多次读取。最小化序列化 :只把渲染必需的数据送进 client,避免大对象或多层嵌套。客户端边界更小更稳定 :避免“页面级 use client”;只包裹交互层。避免笨重的 bundle 引入 :能做到按需加载,就不要把大型模块全量打包到 client。能静态就静态,能流式就流式 :在 server 组织结构,在 client 做增量。
如果你在项目里已经感到“复杂度开始上涨”,通常是边界变大、请求串行、序列化过多三个问题叠加。
8. 常见误区与修正
误区:用 use client 包住整个页面
修正:把交互拆成小 client 组件,页面主体留在 server。
误区:把数据获取放在 client
修正:把 fetch 拉回 server,配合 Suspense 与缓存。
误区:跨边界传递复杂对象
误区:把 Server Action 当普通函数
修正:视作 API 层,定义输入输出、错误、幂等与日志。
9. 小结
RSC 是一种新的树组织方式 :
Server Components 负责结构与数据;
Client Components 负责交互;
use client 是边界,use server 是动作,use cache 是复用。
当你开始用“结构正确性”代替“性能直觉”,RSC 的优势会变得自然:代码更清晰,渲染更稳定,系统更可演进。