z0 的第一个用户,也就是我自己,在第三天就提了一个 bug:连续对话中,Agent 会反复问已经回答过的问题。Session Memory 确实在工作,但它本质上只是一个 conversation buffer。Agent 知道“刚才说了什么”,却不知道“上次 session 确认过什么”,更不知道“这个项目的全局规则是什么”。
这不是 RAG 的经典问题,也不是“检索不到相关文档”那么简单。更底层的问题是:Agent 需要的不是一个知识库,而是一套分层的记忆系统;每一层的写入逻辑、检索策略和生命周期都不同。
这篇文章记录 @z0/memory 从设计到实现的过程,包括哪些选择是有意为之,哪些是踩坑之后的妥协。
如果用一句话概括,它不是在“给 Agent 加一个知识库”,而是在给 Agent 建立一套有层级、有生命周期、会自我修正的记忆检索系统。
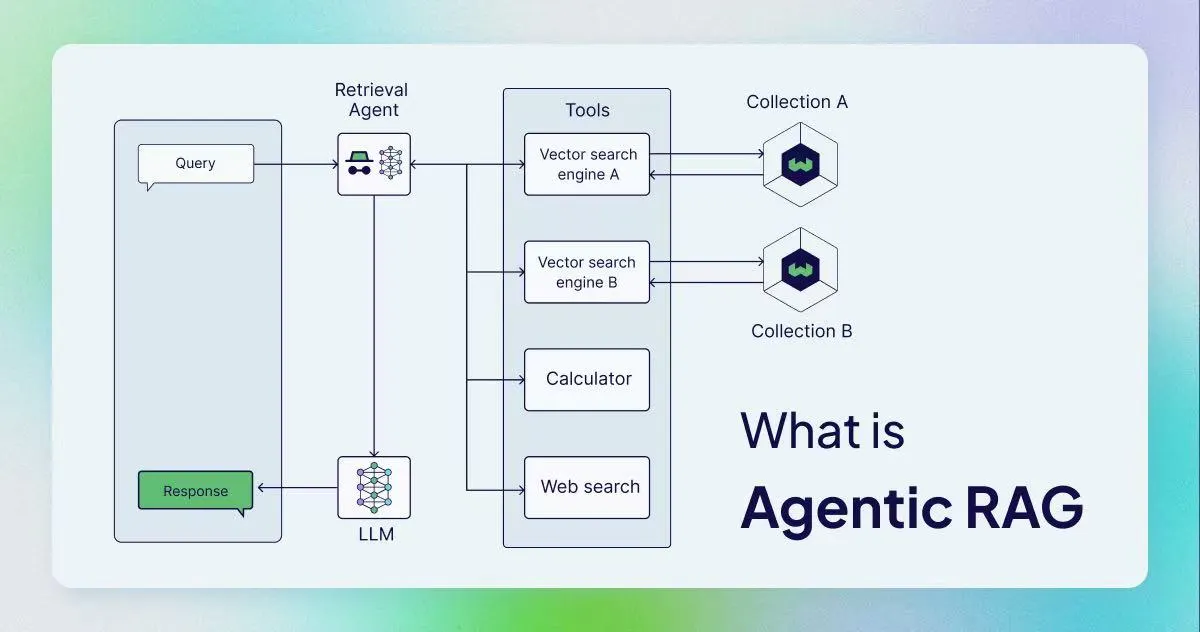
图1:Agentic RAG 作为文章的总览入口,放在开头帮助先建立整体心智模型。
背景:为什么传统 RAG 不够
RAG 的核心是“检索器 + 生成器”:把外部知识编码成向量,用相似度检索后喂给 LLM。这在知识库问答里很有效,但 Agent 系统面对的是另一类需求:
- 记忆有层级:项目规则不需要每次检索,它应该始终存在;上周确认的技术选型需要跨 session 保留;当前对话的上下文在几分钟后就应该过期。
- 写入是隐式的:用户不会主动说“请记住这个”。Agent 需要自己判断哪些信息值得持久化。
- 检索需要自省:Agent 搜了一次没搜到,应该换个方式再搜,而不是直接告诉用户“我找不到”。
传统 RAG 往往把所有外部知识都放进一个向量库,并试图用一次检索解决问题。对于 Agent 来说,这个抽象太粗糙了。
@z0/memory 的三层架构
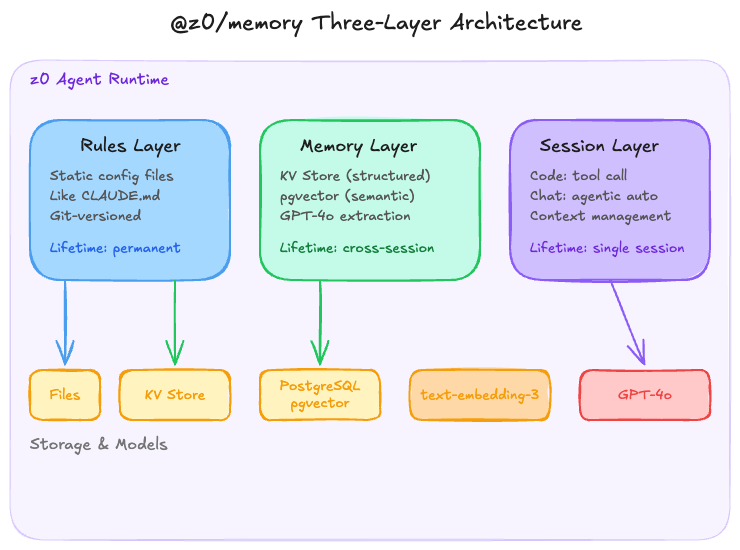
图2:@z0/memory 的三层架构,对应系统规则、长期记忆和会话记忆。
Layer 1:Rules(系统记忆)
最简单的一层。静态配置文件,功能上类似 Claude 的 CLAUDE.md 或 Cursor 的 .cursorrules:项目规则、代码规范、技术栈约束,手动维护,启动时加载进 system prompt。
这里没有什么花哨的技术。之所以选择静态文件而不是数据库,是因为这类信息的更新频率极低,通常是天级别或周级别。用 Git 管理版本,比额外引入数据库更合理。Agent 也不应该自动修改这一层,因为项目规则是人类的决策,不是 Agent 的推断。
Layer 2:Memory(长期记忆)
这是核心层,也是工程量最大的一层。底层用了双存储架构。
KV 存储负责结构化事实。比如“用户确认使用 Hono 而不是 Express 作为后端框架”,这种信息是确定性的、可覆盖的,适合 key-value 模型。Key 的 namespace 设计直接决定检索效率,所以我按 {project}:{category}:{entity} 分层,优先走精确匹配,而不是一上来就模糊检索。
pgvector 负责非结构化语义记忆。对话里产生的推断、偏好、上下文片段,做 embedding 之后直接写进 PostgreSQL 的 pgvector 扩展。我选 pgvector 而不是 Pinecone、Qdrant 这类专用向量库,原因很务实:z0 的主数据库本来就是 PostgreSQL(Supabase),在同一个实例上加扩展意味着零额外运维,事务一致性也更自然,JOIN 查询不需要跨服务。embedding 模型则用 OpenAI 的 text-embedding-3。
真正难的不是存,而是写。什么才值得记住? 这里我用 GPT-4o 做 extraction。每轮对话结束后,一个轻量 extraction prompt 会判断当前是否产生了新的事实、决策或偏好;如果有,再决定写入 KV 还是 pgvector。
这个判断并不总是准确。早期版本有明显的过度记忆问题,用户随口一句“也许可以试试 Redis”,就会被当成正式技术决策写进去。后来我加了一层 confidence threshold:extraction 模型除了产出候选记忆,还必须给出 confidence score。低于阈值的候选只做标记,不立即持久化,等后续对话再次确认后再落盘。
Layer 3:Session(会话记忆)
Session 层处理当前对话的上下文,但它不只是一个 conversation history buffer。
在 Code Agent 模式下,Session Memory 的访问方式是 tool call。也就是说,Agent 需要主动决定“我现在要查一下之前的上下文”,而不是每次都自动注入全部历史。这是一个有意的设计:Code Agent 的单次任务通常非常聚焦,比如“修这个 bug”或者“重构这个模块”。如果把 30 轮对话历史全部塞进上下文,不仅浪费 token,还会引入大量噪声。让 Agent 自己决定何时回溯,token 效率更高。
而在 Chat 模式下,我更倾向于 Agentic Memory,也就是系统自动管理上下文注入。聊天场景下,用户天然期待 Agent “记住”之前说过的话;如果要求它手动 tool call 才能想起来,对话会非常不自然。
对抗式检索闭环
这是 @z0/memory 里我认为最值得讲的部分。
传统 RAG 的检索通常是单次的:query → embedding → top-k → 塞进 context。如果 top-k 结果不相关或不充分,模型要么开始幻觉,要么直接说“我不知道”。
z0 的检索层借鉴了 GAN 的思路,但不是图像生成意义上的 GAN,而是对抗式评估这个核心机制:一个 Agent 负责检索(Generator),另一个 Agent 负责评估当前检索结果是否足以回答问题(Discriminator)。
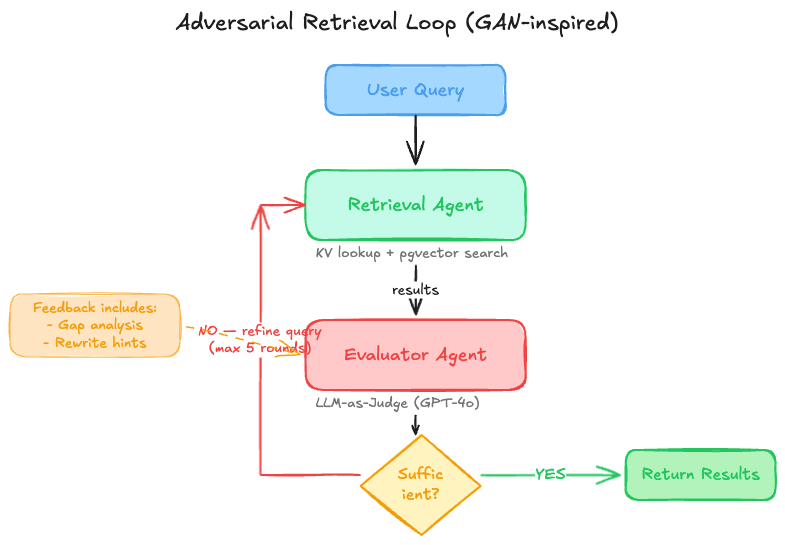
图3:对抗式检索闭环,Retriever 负责找内容,Evaluator 负责挑出“还不够”的地方。
完整流程是这样的:
- Retrieval Agent 根据当前 query 执行检索,必要时同时查询 KV 和 pgvector。
- Evaluator Agent 判断这些结果是否足够回答原问题。这里我用 GPT-4o 做 LLM-as-Judge,要求它输出三件事:是否充分、为什么不充分、下一轮应该怎样改写。
- 如果结论是不充分,Retrieval Agent 会根据 Evaluator 的反馈改写 query,或者直接切换策略,比如从语义检索改成 KV 精确查询,再跑一轮。
- 最多重试 5 轮。这个上限是经验值。超过 3 轮之后,命中率的边际提升已经不大,但某些多跳问题确实需要多一点空间,所以我保留到 5 轮。
之所以叫“对抗式”,是因为 Evaluator 的职责不是帮当前结果找理由证明“已经够好了”,而是主动寻找不足。prompt 设计里我刻意让它保持怀疑态度,这和 GAN 里 Discriminator 的角色很像:它的工作是挑毛病,直到真的挑不出来。
这套机制的现实 tradeoff
好处很直接。对于复杂问题,比如“这个项目之前为什么从 Express 切到了 Hono?当时考虑了哪些因素?”,单次检索几乎不可能一次命中全部相关记忆片段。闭环检索给了系统逐步拼出完整上下文的机会。
代价也非常现实:
- Latency:每多一轮就是一次额外的 LLM 调用。最坏 5 轮时,检索链路的延迟很容易来到 5 到 8 秒。在 Code Agent 模式下这还可以接受,因为用户本来就在等待 Agent 执行任务;但放到 Chat 模式里,体感会明显变差。所以目前 Chat 模式的最大轮数只设成了 3。
- 成本:让 GPT-4o 做 Evaluator 并不便宜。我正在评估能否用
gpt-4o-mini替代。评估“结果够不够”所需的推理能力,理论上比决定“怎么检索”更低,小模型可能已经足够,但还没有完成严格的质量对比。 - 过度检索:Evaluator 有时会过于严格,对已经足够可用的结果仍然判定为“不充分”,触发没有必要的 retry。这个问题目前主要靠 prompt 调优持续压制。
和纯 Agentic RAG 概念的对应关系
如果你读过 Agentic RAG 的概念文章,会发现 z0 的实现大致能对上这些角色:
- Routing Agent:z0 里没有做成独立 Agent,而是由 Gateway 层根据 query 类型决定走 KV 精确查询还是 pgvector 语义检索。
- Query Planning Agent:由 Retrieval Agent 承担 query 改写和策略切换。
- ReAct 闭环:对应 Retrieval-Evaluation 的对抗循环,最多 5 轮。
- Plan-and-Execute:对应 z0 主循环的 Plan / Execute / Feedback 架构,而 memory 系统是 Execute 阶段里的一个 tool。
但我不会把 z0 描述成一个“标准的 Agentic RAG 系统”。很多文献里提到的能力,比如多智能体协作、跨数据源联邦检索、自动工具发现,z0 现在都没有实现,而且这个阶段也不打算实现。对记忆系统来说,可靠性和可调试性比架构复杂度更重要。
目前没做,但已经排进计划
- Rerank 层:现在 pgvector 的结果还是直接按余弦相似度排序,没有 rerank。后面可能会引入 LLM-based rerank,甚至直接复用 Evaluator 的能力,一边评估充分性一边辅助排序,但要先确认额外 latency 是否值得。
- Memory Decay:长期记忆目前没有过期机制。理论上,半年前已经被覆盖的技术决策应该自动降权,但“什么时候算过期”这件事还没有足够好的判断逻辑。
- Evaluator 降级实验:尝试用
gpt-4o-mini替代 GPT-4o 做检索评估,目标是把成本降下来。前提是先构建一套评估数据集,能量化两者在召回质量上的差异。
结论
构建 Agent 记忆系统的核心挑战,不是“怎么做一个 RAG”,而是怎么设计信息的生命周期:什么应该永久存在,什么应该跨 session 保留,什么应该随着对话结束自然消失;以及怎么让检索系统自己知道‘还不够’。
z0 现在的方案当然不是最优解。对抗式闭环的 latency 成本,在高频交互场景下仍然明显;Evaluator 的判断标准,也还在持续调优。但至少它解决了最开始那个非常具体的问题:Agent 不再反复问已经确认过的问题了。
如果你也在做 Agent 系统的记忆层,我的建议很简单:先想清楚你的记忆有几种生命周期,再决定用什么技术。向量库和 embedding 模型是工具,不是架构。