z0's first user, which was me, filed a bug on day three: across continuous conversations, the Agent kept asking questions that had already been answered. Session Memory was doing its job, but at its core it was only a conversation buffer. The Agent knew what had just been said, but it did not know what had been confirmed in the previous session, and it certainly did not know what the global rules of the project were.
This is not the classic RAG problem, and it is not as simple as “the system failed to retrieve the right document.” The deeper problem is this: an Agent does not need a knowledge base. It needs a layered memory system, and each layer has different write logic, retrieval strategy, and lifecycle semantics.
This article documents how @z0/memory moved from design to implementation, including which choices were deliberate and which ones were compromises forced by mistakes in earlier versions.
In one sentence, this is not about “adding a knowledge base to an Agent.” It is about building a layered memory and retrieval system with explicit lifecycles and a self-correcting loop.
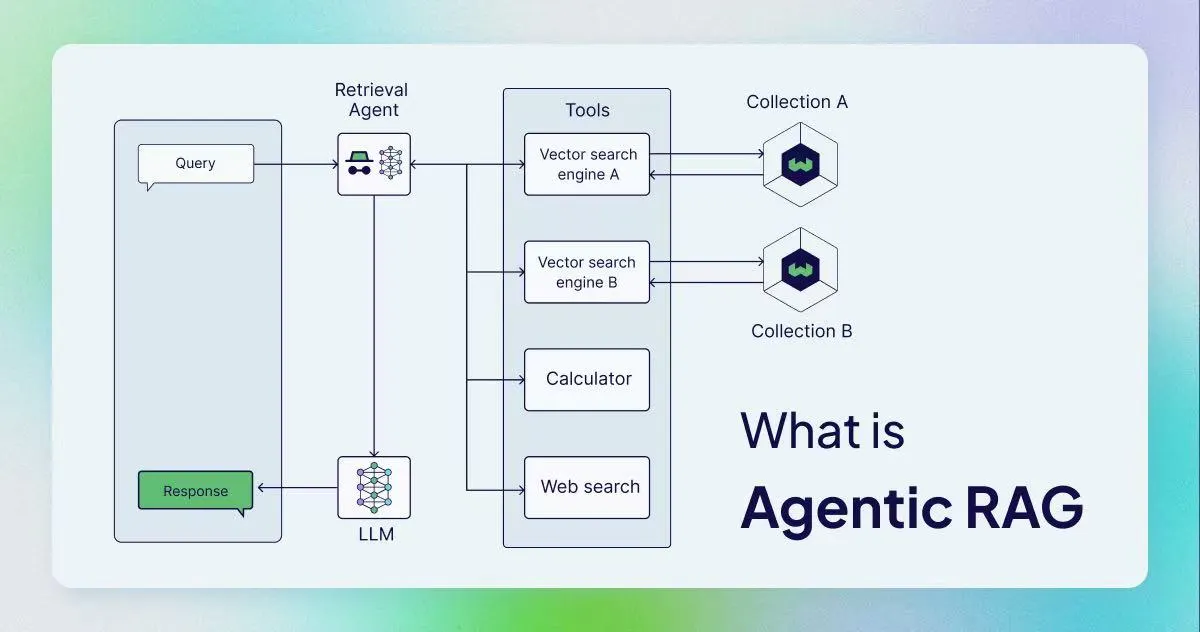
Figure 1: A high-level Agentic RAG overview placed up front to establish the full mental model first.
Background: Why Traditional RAG Is Not Enough
At the core of RAG is “retriever + generator”: encode external knowledge into vectors, retrieve by similarity, and feed the result to an LLM. That works well for knowledge-base question answering, but Agent systems face a different class of requirements:
- Memory has layers: project rules should not need retrieval on every turn; they should always exist. Technical decisions confirmed last week need to survive across sessions. The active conversational context should expire a few minutes later.
- Writes are implicit: users do not explicitly say “please remember this.” The Agent has to decide on its own what is worth persisting.
- Retrieval needs self-reflection: if one search fails, the Agent should try a different retrieval path instead of immediately responding with “I can’t find it.”
Traditional RAG usually dumps all external knowledge into one vector store and tries to solve the problem with a single retrieval pass. For Agents, that abstraction is too coarse.
The Three-Layer Architecture of @z0/memory
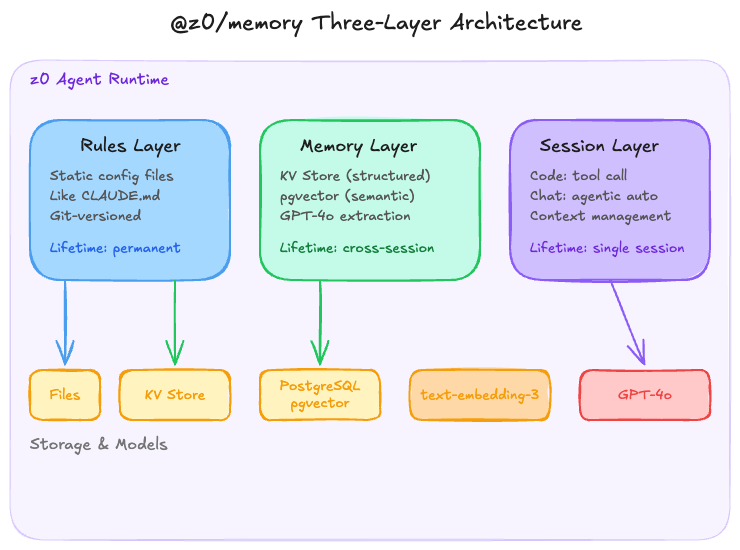
Figure 2: The three-layer architecture of @z0/memory, spanning rules, long-term memory, and session memory.
Layer 1: Rules (System Memory)
This is the simplest layer. It is a static configuration file, functionally similar to Claude's CLAUDE.md or Cursor's .cursorrules: project rules, coding conventions, and stack constraints, maintained manually and loaded into the system prompt at startup.
There is nothing fancy here. I chose static files over a database because this kind of information changes very slowly, usually on the scale of days or weeks. Versioning it in Git is more reasonable than introducing another storage system. The Agent should not modify this layer automatically because project rules are human decisions, not Agent inferences.
Layer 2: Memory (Long-Term Memory)
This is the core layer and also the most substantial engineering effort. Under the hood, it uses a dual-storage design.
KV storage handles structured facts. For example, “the user confirmed Hono instead of Express as the backend framework.” This sort of information is deterministic and overwriteable, so it fits a key-value model well. The key namespace design directly affects retrieval efficiency, so I partitioned it as {project}:{category}:{entity} and prioritized exact matching before fuzzy lookup.
pgvector handles unstructured semantic memory. Inferences, preferences, and context fragments produced during conversations are embedded and written into PostgreSQL through the pgvector extension. I chose pgvector instead of dedicated vector stores like Pinecone or Qdrant for pragmatic reasons: z0's primary database is already PostgreSQL via Supabase, so adding pgvector in the same instance means zero extra ops overhead, more natural transaction consistency, and no cross-service joins. The embedding model is OpenAI's text-embedding-3.
The real difficulty is not storage but write decisions. What is worth remembering? I use GPT-4o for extraction. At the end of each conversational turn, a lightweight extraction prompt decides whether the turn produced a new fact, decision, or preference. If so, it decides whether the result belongs in KV or pgvector.
That judgement is not always accurate. Early versions had an obvious over-memory problem: a casual line like “maybe we could try Redis” was captured as if it were a formal technical decision. I later added a confidence threshold. The extraction model must now output a confidence score alongside the candidate memory. Anything below the threshold is marked but not persisted until a later turn confirms it.
Layer 3: Session (Session Memory)
The Session layer handles the current conversational context, but it is not just a conversation history buffer.
In Code Agent mode, Session Memory is accessed through tool calls. The Agent explicitly decides, “I need to look up earlier context now,” instead of receiving the entire history automatically every time. That choice is deliberate: single Code Agent tasks are usually narrow, such as “fix this bug” or “refactor this module.” Injecting 30 turns of history into context every time wastes tokens and adds noise. Letting the Agent decide when to backtrack is more token-efficient.
In Chat mode, I lean toward Agentic Memory, where the system manages context injection automatically. In conversational settings, users expect the Agent to “remember” prior turns. Requiring explicit tool calls would make the interaction feel unnatural.
The Adversarial Retrieval Loop
This is the part of @z0/memory that I think is most worth explaining.
Traditional RAG retrieval is usually single-shot: query → embedding → top-k → context injection. If the top-k results are irrelevant or incomplete, the model either starts hallucinating or says “I don't know.”
z0's retrieval layer borrows from the logic of GANs, though not in the image-generation sense. What it borrows is the core mechanism of adversarial evaluation: one Agent is responsible for retrieval (the Generator), and another Agent is responsible for judging whether the current retrieval result is sufficient to answer the question (the Discriminator).
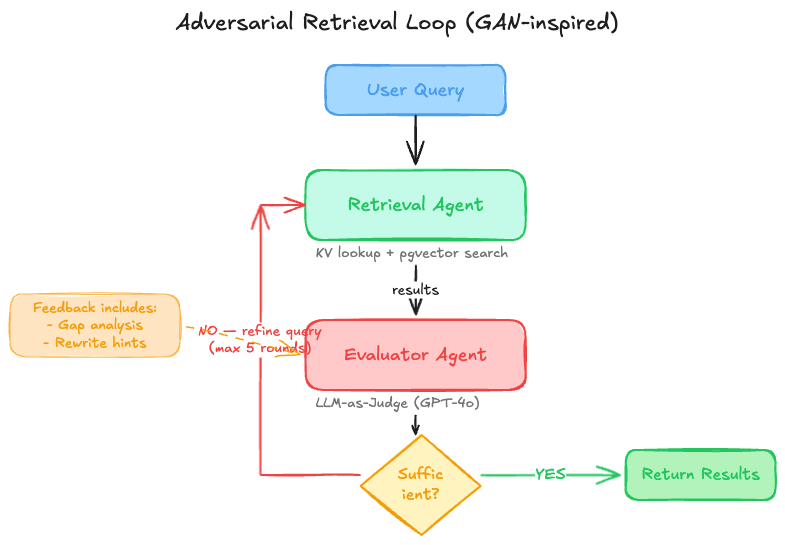
Figure 3: The adversarial retrieval loop, where the Retriever searches and the Evaluator keeps identifying what is still missing.
The concrete flow looks like this:
- The Retrieval Agent executes retrieval for the current query, and may query both KV and pgvector when needed.
- The Evaluator Agent decides whether the result is sufficient to answer the original question. I use GPT-4o here as an LLM-as-Judge and ask it to output three things: a sufficient/insufficient judgement, the exact reason it is insufficient, and a suggested direction for rewriting.
- If the result is insufficient, the Retrieval Agent rewrites the query based on that feedback or switches strategy altogether, for example from semantic retrieval to KV exact lookup, and runs another round.
- The loop stops after five rounds at most. That cap is empirical. After three rounds, the marginal gain in hit rate becomes small, but some multi-hop questions do benefit from more room, so I left the upper bound at five.
Why call it “adversarial”? Because the Evaluator is not meant to defend the current retrieval result and justify why it is “good enough.” Its job is to actively search for what is missing. The prompt intentionally pushes it into a skeptical stance, much like the Discriminator in a GAN: it keeps finding faults until it genuinely cannot find any.
The Real-World Tradeoffs of This Design
The upside is straightforward. For complex questions like “why did this project move from Express to Hono, and what factors were considered at the time?”, a single retrieval pass is very unlikely to hit every relevant memory fragment. The loop gives the system a chance to assemble the picture incrementally.
The costs are equally real:
- Latency: every extra round means another LLM call. In the worst case, five rounds can push retrieval latency into the 5-8 second range. In Code Agent mode that is still acceptable because the user is already waiting for the Agent to do work. In Chat mode it becomes painful, so the current max round count there is set to 3.
- Cost: using GPT-4o as the Evaluator is not cheap. I am considering replacing it with
gpt-4o-mini. Judging whether evidence is “enough” should theoretically require less reasoning than deciding how to retrieve, so a smaller model may be sufficient, but I have not yet completed a rigorous quality comparison. - Over-retrieval: sometimes the Evaluator is too strict and labels a clearly usable result as insufficient, triggering unnecessary retries. This remains an ongoing prompt-tuning problem.
How It Maps to Agentic RAG Concepts
If you have read the conceptual literature around Agentic RAG, the z0 architecture roughly lines up like this:
- Routing Agent: in z0 this is not a standalone Agent. The Gateway layer decides whether a query should go to KV exact lookup or pgvector semantic retrieval.
- Query Planning Agent: the Retrieval Agent takes responsibility for query rewriting and strategy switching.
- ReAct loop: this corresponds to the Retrieval-Evaluation adversarial cycle, with a maximum of five rounds.
- Plan-and-Execute: this maps to z0's main Plan / Execute / Feedback loop, where memory is one tool inside the Execute stage.
That said, I would not describe z0 as a “standard Agentic RAG system.” Many abilities discussed in the literature, such as multi-agent collaboration, federated retrieval across data sources, and automatic tool discovery, are not implemented in z0 today, and I do not intend to implement them at this stage. For a memory system, reliability and debuggability matter more than architectural complexity.
What Is Still Missing but Already Planned
- A rerank layer: today pgvector results are still sorted directly by cosine similarity, without reranking. I may introduce LLM-based reranking later, potentially by reusing the Evaluator while it judges sufficiency, but only if the extra latency is justified.
- Memory decay: long-term memory currently has no expiration mechanism. In theory, a technical decision from six months ago that has already been superseded should lose weight automatically, but I still do not have a clean rule for deciding when something is truly stale.
- Evaluator downgrade experiments: I want to test replacing GPT-4o with
gpt-4o-minifor retrieval evaluation to reduce cost. That requires a benchmark dataset first so the quality gap can be measured rather than guessed.
Conclusion
The core challenge of building memory systems for Agents is not “how do I do RAG,” but how do I design the lifecycle of information: what should exist permanently, what should survive across sessions, what should disappear when the conversation ends, and how can retrieval know by itself that it still does not have enough.
z0's current approach is not an optimal endpoint. The latency cost of the adversarial loop is still noticeable in high-frequency interactions, and the Evaluator's standards still need tuning. But it at least fixed the original, concrete bug: the Agent no longer keeps asking questions that were already confirmed.
If you are also building the memory layer of an Agent system, my advice is simple: decide how many lifecycles your memory actually has before you decide what technology to use. Vector databases and embedding models are tools, not architecture.